Ling-2.6-flash Release: Faster Response, Stronger Execution, Higher Token Efficiency
As agent capabilities continue to mature, the rapid growth in token consumption is becoming one of the central challenges in the practical deployment of large language models. Compared to traditional chat scenarios, the input length for agent tasks often increases by two orders of magnitude. At the same time, frequent tool calls, multi-turn planning, and long-term execution further extend the model’s output pipeline. This means that in real-world applications, models not only face greater computational demands for inference but also incur higher costs for end-users.
On the other hand, to further push the upper limits of capabilities, mainstream models in the industry are generally adopting a “long-consideration” approach—trading longer reasoning processes for higher task ceilings. But the question is: For everyday, high-frequency agent usage scenarios, is such a massive number of reasoning tokens really always necessary?
Based on this real-world challenge, we are officially launching Ling-2.6-flash—an Instruct model with a total parameter count of 10.4 billion and 7.4 billion active parameters. Faced with ever-increasing token demands, Ling-2.6-flash has chosen a different technical path: rather than simply relying on longer outputs to achieve higher scores, it takes a systematic approach to optimizing inference efficiency, token efficiency, and agent performance in real-world scenarios. While maintaining a competitive level of intelligence, it strives to be faster, more resource-efficient, and better suited for actual business applications.
Specifically, Ling-2.6-flash’s core capabilities are reflected in three aspects:
-
Hybrid Linear Architecture for Enhanced Inference Efficiency: By adopting a hybrid linear architecture, the model optimizes computational efficiency at the underlying level. Under 4-H20 card conditions, its inference speed can reach up to 340 tokens/s, and its prefill throughput is 2.2 times that of Nemotron-3-Super, enabling it to complete tasks with a higher “cost-effectiveness ratio.”
-
Optimized Token Efficiency, Enhancing Intelligence-to-Effectiveness Ratio: During training, we conducted targeted calibration of token efficiency, striving to achieve our objectives with a more concise output. In a comprehensive evaluation by Artificial Analysis, Ling-2.6-flash consumed only 15M tokens, roughly one-tenth of the tokens used by models such as Nemotron-3-Super—yet it accomplished the task with a significantly higher “intelligence-to-effectiveness ratio.”
-
Targeted Enhancements for Agent Scenarios: Focusing on agent applications that currently have the highest demand, we’ve continuously refined our model’s capabilities in tool calling, multi-step planning, and task execution. As a result, in benchmarks such as BFCL-V4, TAU2-bench, SWE-bench Verified, Claw-Eval, and PinchBench, our model consistently achieves performance that is comparable to—or even at SOTA levels—despite being applied to models with significantly larger activation parameters.
This also means that Ling-2.6-flash is not striving for peak performance in isolation, but rather maintaining strong competitiveness in agent tasks while keeping token consumption under control. For developers and enterprises, this translates into lower inference costs, higher deployment efficiency, and a model experience that’s better suited for large-scale, real-world applications.

Ling-2.6-flash achieves state-of-the-art (SOTA) performance on agent-related benchmarks at the same model size, while maintaining outstanding performance in other core capabilities as well.
01 Hybrid Linear Architecture, Unleashing Inference Efficiency
Architecture Improvement
Ling-2.6-flash retains the model architecture design of Ling 2.5: it introduces a hybrid linear attention mechanism based on the Ling 2.0 architecture. Through incremental training, the GQA attention mechanism in the Ling 2.0 architecture is upgraded to an efficient hybrid architecture—MLA + Lightning Linear—with a ratio of 1:7.
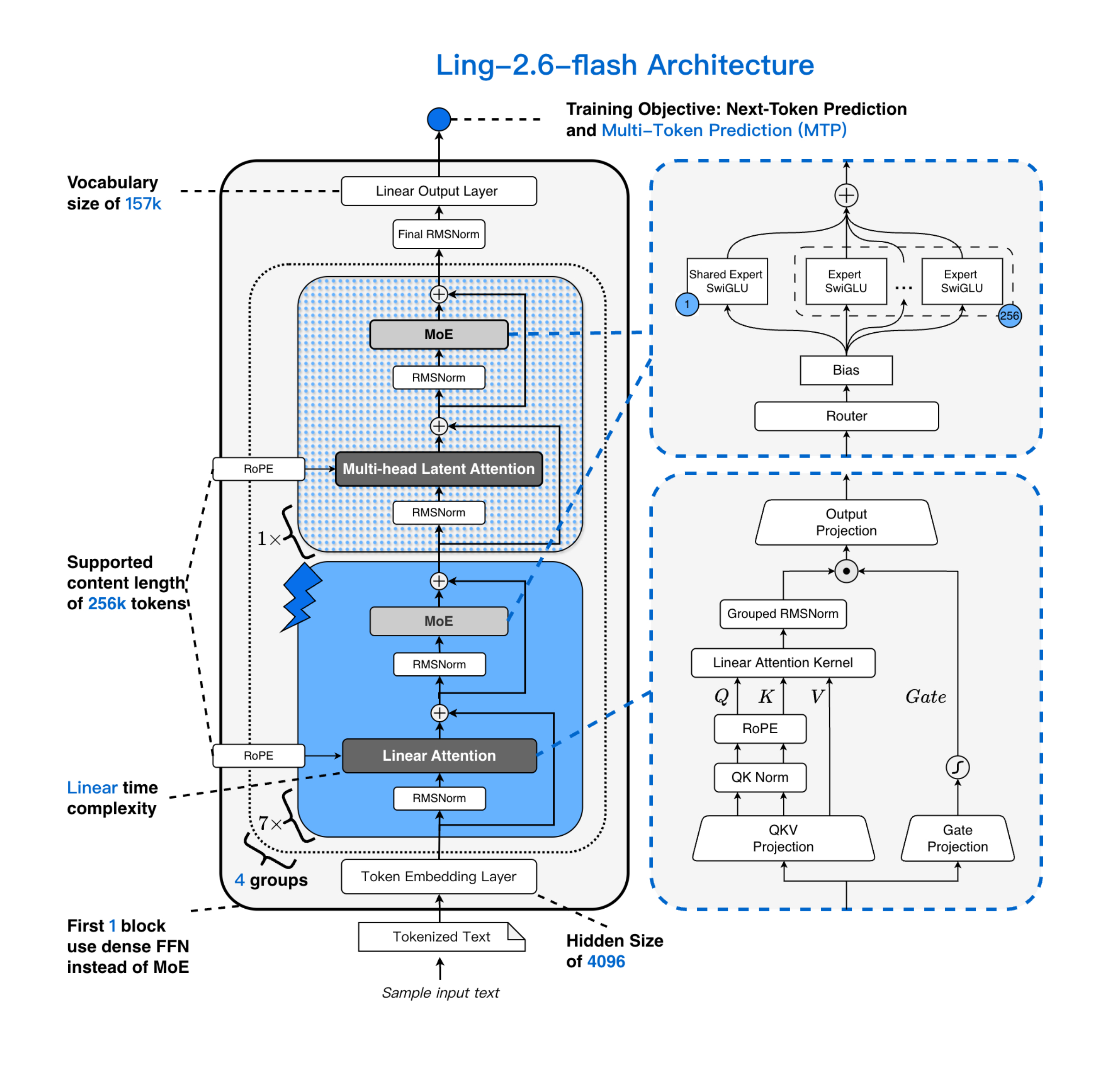
Thanks to the hybrid attention mechanism and the highly sparse MoE architecture, Ling-2.6-flash demonstrates remarkable advantages in inference efficiency. Compared with mainstream state-of-the-art models of similar size, Ling-2.6-flash not only responds faster to the first token but also achieves higher generation efficiency in long-output scenarios—its prefill throughput and decode throughput can both be improved by up to approximately 4 times.
As shown in the figure below, as both the context length and generation length continue to increase, Ling-2.6-flash’s throughput advantage becomes even more pronounced. Moreover, Ling-2.6-flash’s superiority is not limited to static metrics—it consistently delivers greater speed gains in real-world deployment environments as task complexity rises. Whether it’s long-context understanding or continuous generation of lengthy texts, Ling-2.6-flash can maintain model performance while delivering faster response times, higher throughput, and significantly improved practical deployment efficiency.

Comparison of decoding throughput advantages: four H20-3e cards, TP=4, Batch Size = 32

Input (Prefill) Throughput Comparison: Four-card H20-3e, TP=4, Batch Size = 32
Inference Efficiency Optimization
During the pre-training phase of Ling-2.6-flash, we significantly improved training efficiency through large-scale operator fusion. On the inference side, we further conducted in-depth adaptation tailored to real-world deployment scenarios, ensuring that the fused operators remain as consistent as possible with the training side in terms of fusion granularity, implementation paths, and numerical behavior. This design not only delivers higher inference efficiency but also further enhances training-inference consistency during the RL Rollout stage. The relevant inference operators will be open-sourced gradually along with linghe.
We have systematically optimized the inference pipeline to suit different precision scenarios.
-
For BF16 inference, we have achieved deep integration of key operators such as QK Norm + RoPE and Group RMSNorm + Sigmoid Gate, and adopted a computation approach of BF16 Input + FP32 Output in both MoE Router GEMM and LM Head GEMM. We have also optimized the implementations of MLA RoPE and Top-K.
-
For FP8 inference, we further integrate RMSNorm, SwiGLU, and quantization operators, and introduce Split-K Blockwise FP8 GEMM specifically for small batch size scenarios, thereby unlocking even greater throughput potential. This represents a comprehensive system-level collaborative optimization—from operator fusion and cache mechanisms to multi-token generation. The end result is not only higher system throughput, but also higher per-user TPS, shorter latency, and a more stable and smoother user experience in real-world interaction scenarios.
| Baseline (tokens/s) | MTP (tokens/s) | MTP+linghe (tokens/s) | |
|---|---|---|---|
| BF16(BS=1) | 186 | 257 (+38%) | 297 (+60%) |
| BF16(BS=16) | 1075 | 1114 (+4%) | 1233 (+15%) |
| FP8(BS=1) | 155 | 236 (+51%) | 341 (+119%) |
| FP8(BS=16) | 1078 | 1173 (+9%) | 1664 (+54%) |
In the official benchmark of the Artificial Analysis leaderboard under the Output Speed dimension, Ling-2.6-flash ranks among the top performers, achieving an output speed of 215 tokens/s when compared to mainstream models at similar parameter scales, demonstrating its leading generation efficiency. Comparison Data
The comparison scores are sourced from Artificial Analysis
02 Token Efficiency Optimization, Enhancing Intelligence-to-Effectiveness Ratio
In Artificial Analysis (AA)‘s comparison of Intelligence vs. Output Tokens, Ling-2.6-flash demonstrates a remarkable advantage in token efficiency.
As shown in the figure, Ling-2.6-flash achieves an Intelligence Index of 26 points with just 15M output tokens, maintaining a strong level of intelligence while keeping its output costs relatively low. Compared to models that rely on longer outputs to achieve higher scores, Ling-2.6-flash strikes a better balance between “intelligent performance” and “output cost.” This means that the competitiveness of Ling-2.6-flash lies not only in its individual capabilities but also in its overall efficiency optimization for real-world applications. Rather than stacking scores through excessively lengthy outputs, Ling-2.6-flash completes tasks with more concise generation, significantly reducing token consumption while still delivering competitive intelligent performance.
For developers and enterprise scenarios, the value this capability brings is direct and clear: lower inference overhead, faster first-word response, shorter overall generation latency, and a smoother interaction experience. Whether it’s agent calls, complex task execution, or high-frequency online services, Ling-2.6-flash is better suited to meet the comprehensive demands for speed, cost, and user experience in real-world deployment environments.
In other words, Ling-2.6-flash doesn’t simply aim for “greater strength”; rather, building on being “strong enough,” it further strives to be “faster, more efficient, and more practical.”

The comparison scores are sourced from Artificial Analysis.
From the perspective of token consumption, Ling 2.6 Flash demonstrates a significant improvement in intelligence efficiency.
In the comprehensive evaluation of the Artificial Analysis Intelligence Index, Ling-2.6-flash demonstrated significantly superior token efficiency: its total token consumption was only 15M tokens, whereas models such as Nemotron-3-Super reached or exceeded 110M tokens. In other words, Ling-2.6-flash completed the same evaluation task using approximately one-tenth the token consumption, reflecting a more streamlined output approach and a higher intelligence-to-token ratio.

Targeted Enhancement for Agent Scenarios
Agent Optimization
To enhance the capabilities of our model agent, we have significantly expanded both the difficulty and breadth of the training data for Ling-2.6-flash, thereby optimizing its performance on complex, long-term tasks. Leveraging our self-developed large-scale, high-fidelity interactive environment, we have conducted targeted reinforcement learning (RL) training on Ling-2.6-flash, focusing specifically on its General Agent and Coding Agent components.
- Significantly improved the model’s performance in instruction following, tool invocation, multi-step planning, and long-term execution, ensuring that the model accurately understands and executes instructions. Ling-2.6-flash has demonstrated outstanding results on benchmark lists such as BFCL-V4, TAU2-bench, SWE-bench Verified, and PinchBench.
- By optimizing the model via RL, we’ve significantly enhanced its generalization and stability across various agent scenarios, greatly improving its application experience in real-world settings. Ling-2.6-flash has demonstrated a great user experience in frameworks such as Claude Code, Kilo Code, Qwen Code, Hermes Agent, and OpenClaw.
The Ling-2.6-flash model maintains an excellent performance across various dimensions, including general knowledge, mathematical reasoning, instruction following, and long-text comprehension. All its metrics align with those of state-of-the-art models of the same size, ensuring robust and high-quality performance in all scenarios.

- PinchBench: The comparison scores are sourced from the official PinchBench leaderboard (as of April 20, 2026), and directly reflect the scores obtained under the official evaluation settings (which may include Reasoning Mode).
- Claw-Eval: Comparison scores are taken from the official Claw-Eval leaderboard (version as of March 25, 2026), using the scores directly under the official evaluation settings (which may include Reasoning Mode). Among these, GPT-OSS-120B and GPT-5.4-mini have not yet been published on the official Claw-Eval leaderboard and thus are not included in the comparison results.
- TAU2-Bench: The evaluation is conducted based on the official v1.0.0 code and dataset. Following the evaluation configuration of GLM-5, we fine-tuned user prompts in the Retail and Telecom domains to ensure clearer expression of user requests and prevent sessions from being terminated prematurely. In addition, GPT-5.2 is used as the User Agent across all domains.
- IFBench: Scores for Qwen3.5-122B-A10B (Non-Reasoning), GPT-OSS-120B (low), and GPT-5.4-mini (Non-Reasoning) are sourced from the Artificial Analysis leaderboard; results for the remaining models come from internal evaluations.
04 Practical Demonstration: Ling-2.6-flash’s Real-Time Execution Capability
Code Scenario
Web Generation
Scene Introduction: Ling-2.6-flash combines high aesthetic expression with rapid code generation capabilities. It can accurately understand and call upon frontend components and icon libraries, making it particularly well-suited for quick validation in single-page demos and prototype development.
The quantized version of INT4 runs on DGX Spark
Scene Introduction: A Tutorial on Building an Industry-Leading SOTA Hermes All-in-One Machine Based on Ling-2.6-flash & DGX Spark
kilocode: Generate a stylized webpage
Scene Introduction: In Kilo Code, Ling-2.6-flash is not just a code generator—it can also quickly transform visual instructions into high-quality interfaces. Combined with Kilo Code’s engineering foundation, it excels at generating personalized visual styles, producing newspaper-quality layouts, and instantly creating office documents such as weekly newsletters and reports, delivering “input equals finished product” while balancing speed and design quality.
Text Scenario
Prompt-driven workflow execution capability
Scene Introduction: Relying solely on prompts, Ling-2.6-flash can effortlessly handle multi-step text tasks, excelling in instruction adherence, tone adjustment, and real-time generation, producing content that is natural and fluent.
Agent Tool Invocation Scenarios
Extraction of a Map of Characters and Events from Dream of the Red Chamber
- Scene introduction: Ling-2.6-flash boasts powerful contextual retrieval, tool invocation, and high-speed response capabilities, making it ideal for complex information processing and knowledge-enhancement scenarios. (There are two videos that can be combined.)
Autonovel: Long-form Novel Writing
autonovel is a long-form novel-writing assistant that covers the entire workflow—from world-building and character development to outline generation and final manuscript creation. Built on Ling-2.6-flash, autonovel further enhances the efficiency of long-form writing, as well as contextual consistency and narrative-driven plot development. It excels in areas such as ultra-long-text generation, seamless integration of foreshadowing, and meticulous content refinement. With an ultra-fast generation speed of over 200 tokens per second, it can produce million-word manuscripts in just a few dozen minutes.
Requirements Gathering and Scheduling
Ling-2.6-flash is designed for real-world work scenarios and can reliably participate in the actual execution of processes such as information retrieval, task breakdown, content processing, and tool collaboration. With a low hallucination rate and high result availability, it not only answers questions but also genuinely takes on tasks and drives workflows forward—making it a practical, “work-ready” model.
05 Limitations and Future Plans
Ling-2.6-flash has made phased progress in exploring the ultimate balance between intelligence and efficiency. The model has demonstrated significant improvements across key dimensions, including tool invocation, multi-step planning, and long-term task execution. Combined with systematic optimizations in inference efficiency and interactive experience, Ling-2.6-flash is now better equipped to handle large-scale, high-frequency automated tasks, showcasing greater practical value in real-world application scenarios.
At the same time, we are also keenly aware that the pursuit of an exceptionally high intelligence-efficiency ratio does come at a cost. In certain highly complex scenarios, due to limitations in inference depth, the model may still exhibit some degree of tool hallucination. Moreover, in areas such as seamless switching between Chinese and English and adherence to complex instructions, Ling-2.6-flash still has room for further optimization.
Looking ahead to future iterations, we will continue exploring the optimal boundaries of intelligence efficiency. While maintaining efficient inference capabilities, we will further promote a deep balance between the quality of intelligent outputs and token efficiency, continuously enhancing the model’s stability, availability, and interactive experience across all scenarios.
06 Usage and Experience
Elephant Alpha (Ling-2.6-flash Anonymous Beta Version) Officially Unveiled
One week ago, the anonymous model codenamed Elephant Alpha was launched on OpenRouter. Since its launch, its usage has been steadily increasing, consistently topping the Trending charts for several days in a row, with daily token usage reaching the 100-billion level. Today, we’re officially unveiling: Elephant Alpha is none other than the anonymous test version of the Bailing model Ling-2.6-flash.

After a week of continuous iteration and optimization, Ling-2.6-flash has further improved its generalization and stability in agent scenarios.
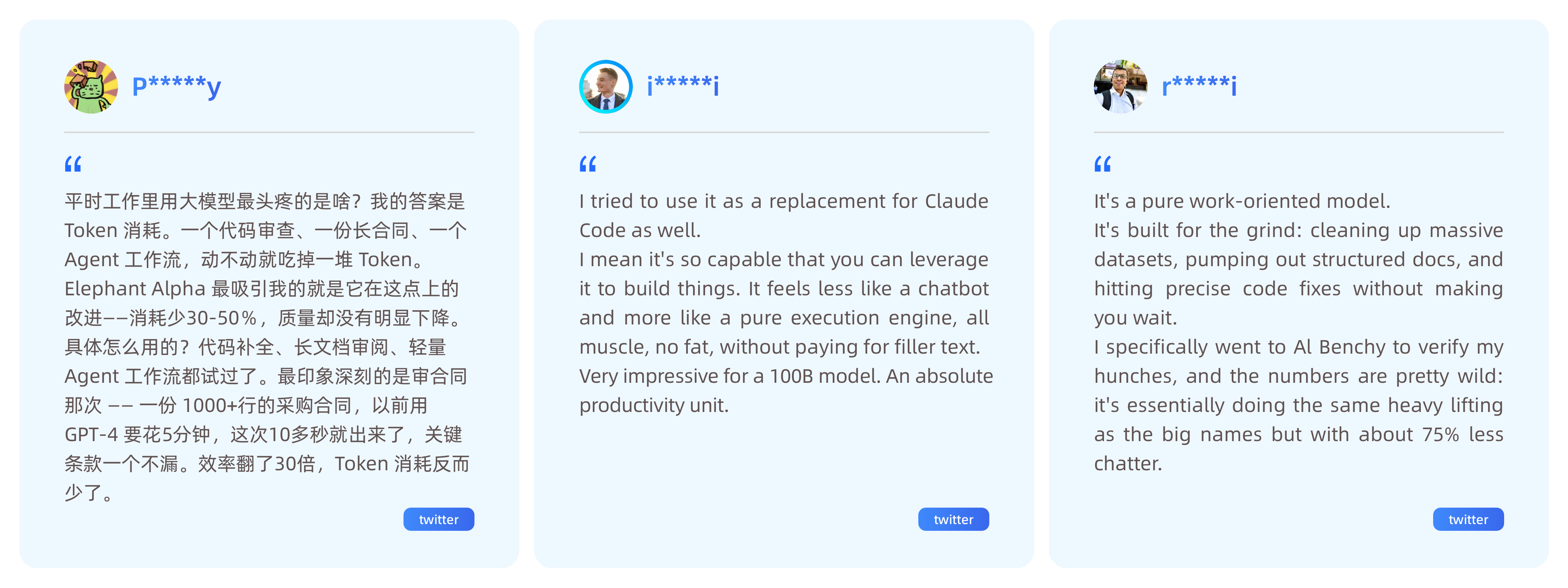
During the Elephant Alpah testing phase, we received genuine feedback from the community and gained widespread recognition for our performance in terms of speed and token consumption.
Connect Now
To enable more developers to quickly experience Ling-2.6-flash, we will provide one week of free API calls on OpenRouter, synchronized with the official platform.
The OpenRouter trial address is: https://openrouter.ai/inclusionai/ling-2.6-flash:free
After the free trial period ends, you’ll be billed based on usage: $0.1 per million tokens for input, $0.3 per million tokens for output, and $0.02 per million tokens for cache hits (billed at 20%).
The official API service for Ling-2.6-flash is now officially available, and the access address is: https://chat.ant-ling.com/chat.
After the official free period ends, the platform will still provide a daily free quota of 500,000 tokens; any usage exceeding this quota will be billed on a pay-as-you-go basis: ¥0.6 per million tokens for input, and ¥1.8 per million tokens for output.
The BF16, FP8, INT4, and other versions of the model will also be officially open-sourced soon—stay tuned!