Introducing Ming-Lite-Omni V1.5
GITHUB 🤗 Hugging Face| 🤖 ModelScope
Overview
Ming-lite-omni v1.5 is a comprehensive upgrade to the full-modal capabilities of Ming-lite-omni(Github). It significantly improves performance across tasks including image-text understanding, document understanding, video understanding, speech understanding and synthesis, and image generation and editing. Built upon Ling-lite-1.5, Ming-lite-omni v1.5 has a total of 20.3 billion parameters, with 3 billion active parameters in its MoE (Mixture-of-Experts) section. It demonstrates highly competitive results in various modal benchmarks compared to industry-leading models.

Performance Comparison
Introduce Ming-lite-omni v1.5
Controllable Image Generation: Pixel-Level Control, Infinite Creativity
Ming-lite-omni v1.5 significantly optimizes Scene Consistency and ID Consistency (Character / Style Consistency) in image editing. When editing human figures, it demonstrates a clear advantage in maintaining scene and character ID. Furthermore, it expands support for perceptual tasks such as generative segmentation, depth prediction, object detection, and edge contour generation.

Depth and Edge Detection
| Original Image | Generated Depth Map | Generated Bounding Boxes | Generated Edge Contours |
|---|---|---|---|
 |  |  | 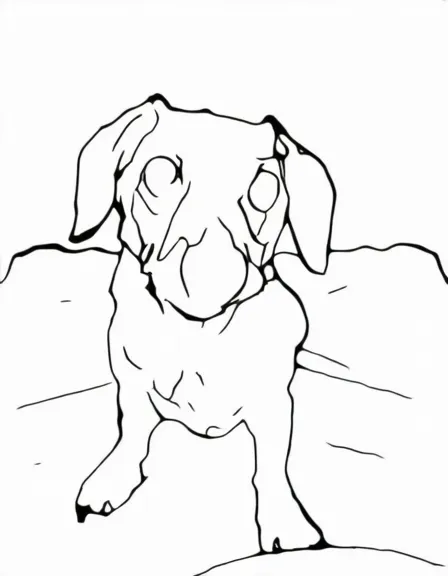 |
Audio-Video Interactive Understanding
Model Architecture Upgrade and Capability Evaluation
The Ming-lite-omni v1.5 model architecture is outlined below. The core design references the structure of Ming-lite-omni V1. However, a key distinction is the upgrade of the Vision head to support reference image feature input, specifically to enhance character and scene consistency in image editing.

Mode Architecture
The model’s capabilities have been significantly optimized and upgraded across three key areas: enhanced Omni-modal comprehension, precise visual editing control, and improved user experience.
Enhanced Omni-Modal Comprehension
Thanks to optimized data quality, Ming-lite-omni v1.5 shows significant improvements in tasks such as vision-text comprehension (including image-text, document, and video understanding) and speech understanding. It has reached an industry-leading level for models of comparable scale.
Vision-text Comprehension
| Task Type | Dataset | Qwen2.5-VL-7B | Ming-lite-omni | Ming-lite-omni v1.5 |
|---|---|---|---|---|
| Image-text Understanding | AI2D | 84.36 | 83.1 | 84.91 |
| HallusionBench | 55.77 | 55.0 | 54.59 | |
| MMBench_TEST_V11 | 82.75 | 80.8 | 80.73 | |
| MMMU | 56.56 | 56.3 | 54.33 | |
| MMStar | 65.27 | 64.7 | 65.07 | |
| MMVet | 71.61 | 71.3 | 73.99 | |
| MathVista | 68.10 | 71.6 | 72.00 | |
| OCRBench | 87.80 | 88.4 | 88.90 | |
| Average | 71.5 | 71.4 | 71.8 | |
| Video Understanding | VideoMME(w/o subs) | 65.10 | 63.4 | 67.07 |
| VideoMME(w/ subs) | 71.60 | 66.01 | 72.59 | |
| VideoMME(avg) | 68.35 | 67.7 | 69.83 | |
| MVBench | 69.60 | 67.7 | 69.43 | |
| LongVideoBench | 56.00 | 56.6 | 59.54 | |
| OvOBench | 51.10 | 48.48 | 52.17 | |
| Average | 61.26 | 58.89 | 62.74 | |
| Document Understanding | ChartQA_test | 87.24 | 85.1 | 88.84 |
| DocVQA_test | 95.57 | 93 | 93.68 | |
| TextVQA_val | 85.06 | 82.8 | 82.27 | |
| OCRBench | 87.8 | 88.4 | 88.9 | |
| Average | 88.91 | 87.32 | 88.42 |
Speech Understanding
| Model | Average(Open-ended QA) | AlpacaEval | CommonEval | SD-QA | MMSU | OpenBookQA | IFEval | AdvBench |
|---|---|---|---|---|---|---|---|---|
| Ming-lite-omni v1.5 | 4.474 | 4.648 | 4.3 | 61.16 | 45.77 | 65.934 | 55.599 | 98.076 |
| Ming-lite-omni | 4.34 | 4.63 | 4.06 | 58.84 | 47.53 | 61.98 | 58.36 | 99.04 |
| MiniCPM-o | 4.285 | 4.42 | 4.15 | 50.72 | 54.78 | 78.02 | 49.25 | 97.69 |
| Kimi-Audio | 4.215 | 4.46 | 3.97 | 63.12 | 62.17 | 83.52 | 61.10 | 100.00 |
| Qwen2.5-Omni | 4.21 | 4.49 | 3.93 | 55.71 | 61.32 | 81.10 | 52.87 | 99.42 |
| GLM-4-Voice | 3.77 | 4.06 | 3.48 | 43.31 | 40.11 | 52.97 | 24.91 | 88.08 |
Precise Visual Editing Control
Ming-lite-omni v1.5 employs the following optimization strategies to address the issues of character ID and scene ID consistency during image editing:
- ID and Scene Consistency Loss: This is achieved by increasing the weight of the edited region in the target image and the reference strength of the non-edited region in the reference image, while simultaneously decreasing the reference strength of the edited region in the reference image. This approach enhances image editing consistency.
- Incorporating Generative Detection and Segmentation Tasks to Boost Perceptual Capabilities: By supporting generative segmentation and keypoint detection, the model’s understanding of image details and spatial relationships is improved. This enhances the structural controllability of the editing and generation processes, leading to significant increases in evaluation metrics related to position, structure, and quantity.
- Multi-Task Collaborative Learning Strategy: Through a joint training pipeline, generation and editing mutually reinforce each other. Segmentation tasks are transformed into colorization editing tasks, which significantly improves segmentation metrics and the precision and controllability of local image editing, resulting in smoother edges for edited regions.
Based on these optimizations, Ming-lite-omni v1.5 shows a significant improvement in image editing capabilities, achieving a GenEval score of 0.87.
| 1-Obj | 2-Obj | Counting | Colors | Position | Color Attr | Avg. | |
|---|---|---|---|---|---|---|---|
| Ming-lite-omni | 0.99 | 0.77 | 0.68 | 0.78 | 0.46 | 0.42 | 0.64 |
| Ming-lite-omni v1.5 | 0.99 | 0.93 | 0.86 | 0.87 | 0.90 | 0.66 | 0.87 |
Optimized User Experience
Thanks to the construction of high-quality alignment preference data, Ming-lite-omni v1.5 demonstrates a certain advantage over leading models in terms of correctness, relevance, format aesthetics, and fluency of expression for image-text Q&A. Ming-lite-omni v1.5 achieved a win rate of 87.07% against Ming-lite-omni V1 on internal adversarial evaluation sets, indicating a significant optimization in user experience.
| Evaluation Dimension | Qwen2.5-VL-7B | Ming-lite-omni V1.5 |
|---|---|---|
| Relevance | 4.308 | 4.5 |
| Fluency | 4.765 | 4.91 |
| Richness of Content | 3.828 | 3.69 |
| Format aesthetics | 4.727 | 4.8 |
| Correctness | 3.741 | 3.92 |
| Average Score | 4.274 | 4.365 |
Get Started with Ming-lite-omni v1.5
The model and code for Ming-lite-omni v1.5 are now open-source, and we invite everyone to try it out, share feedback, and join the discussion. Looking ahead, we’re excited to announce that a quantized and accelerated version is on the way. This future release will not only further enhance omni-modal performance but also make the model even more lightweight, all while strengthening its multimodal reasoning and generation capabilities. Stay tuned for more updates!