Ling 2.5 Lightning Attention+MLA 混合线性架构改造实践
基模架构设计的核心思路是用更低的理论计算(FLOPs)或真实算力(GPU hours)实现更大的架构效率杠杆(Efficiency Leverage)。在 Ling 2.0 架构的研发过程中,我们通过 Ling Scaling Law [1] 系统性的分析了 MoE 架构高稀疏比、适当的细粒度切分等因素均会带来更优的效率杠杆。因此,我们一方面持续提升 MoE 架构的稀疏度,另一方面通过极致的工程优化来弥补稀疏计算带来的系统瓶颈。
而这一切分析的度量都是建立在常规窗口长度(4K 或 8K)下。但当上下文窗口长度扩展到 32K 以上,计算将逐步从 MoE 层转移到 Attention 层,尤其是达到 256K 或以上时,Full Attention(GQA)是绝对的性能瓶颈。另一方面,我们当下正处于通用智能体时代的转折点,深度思考与多轮工具调用逐渐融合以实现长程执行,同时也带来 Prefill 和 Decode 的上下文长度极速膨胀。我们认为,要实现真正意义的长程执行和持续交付,必须在超长上下文上用更低的计算(理论 FLOPs 和真实算力)实现更大的效率杠杆。
这里的关键点,是对 Attention 进行改造。对 Attention 进行改造一般分为两个路线,即稀疏化和线性化。其中前者未改变 Full Attention 的计算性质,因此更稳健但理论上限更低。后者则彻底改变了计算特性,但理论收益会非常大。我们其实是两个路线都在推进,但选择投入更多的精力在理论上限更高的线性化路线上。
在去年 Ling 2.0 系列开源时,我们同步开源了基于混合线性注意力架构的思考模型,这也是 Ling 2.5 架构的雏形。在这一系列研究中,我们确认了几个关键点。首先,Pure Linear Attention 在表达能力上是有缺陷的,Ling Scaling Law 的分析显示其 Scaling Trend 无法超越 Full Attention。第二,Linear 与 Full Attention 的 Hybrid 是有效的,在常规窗口下,其 Scaling Trend 甚至可以超越 Full Attention。第三,Hybrid Linear Attention 并不会有传言的长上下文处理和多步推理缺陷。第四,Hybrid Linear Attention 只要工程实现和优化做好,在后训练上依然可以达到与 Full Attention 类似甚至更优的效果。最后,通过架构改造 + 继续训练,可以低成本的实现性能无损的 Hybrid Linear Attention 架构。
基于这些观察,我们进一步研发了 Ling 2.5 架构,并将其扩展到万亿参数规模。其中的重点就是将 Ling 2.0 架构的 GQA 实现改造为 1 :7 的 Lightning Attention + MLA 混合线性注意力,一方面可以享受 Lightning Attention 更高效的 Kernel 表现,在超长上下文处理时吞吐大幅提升;另一方面还可以享受 MLA 带来的 KV Cache 压缩,进一步提升推理效率。为了减少架构改造带来的性能损失,我们设计了精细的平滑迁移训练策略并引入高质量数据。
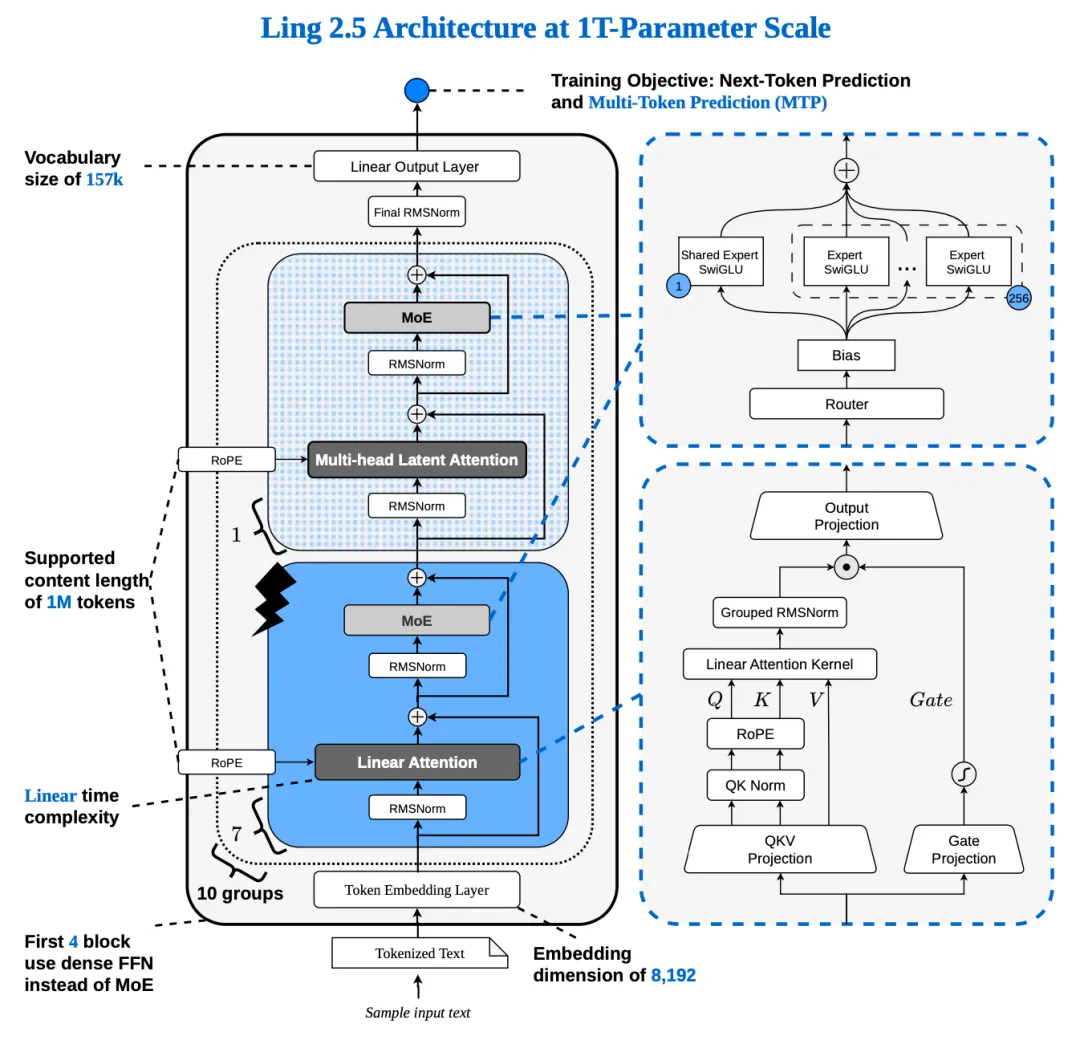
万亿参数规模的 Ling 2.5 架构
1. 核心架构改造:极致的推理与长上下文效率
引入 Lightning Attention,提升长序列效率
沿用 Ring-Flash-Linear-2.0 [2] 技术,我们将 Ling 2.0架构中的部分 GQA(Group-Query Attention)层替换为线性的 Lightning Attention,以大幅提升超长上下文的计算效率。我们通过权重转换将 GQA 维度扩充为标准的 MHA(Multi-Head Attention),对新增的参数进行随机初始化,并在随后的 Warmup 阶段完成参数的平滑对齐与更新,确保模型在架构切换时的稳定性。
集成 MLA,极致压缩 KV Cache
除了提升计算效率,降低显存占用同样关键。相比于 GQA,MLA 能够实现 KV Cache 的极致压缩。
为了验证 MLA 的表征能力,我们在 Ling 2.0 架构的mini(16B-A1.3B)和 flash(和100B-A5B)尺寸上进行了严格的消融实验:将 GQA 全部替换为 MLA,并在原数据上加训 700B tokens,随后在相同的 Mid-Training 数据上再训练 600B tokens。实验表明,模型性能较快恢复并且最终能优于原始的 GQA 版本。此外,我们也在 Ling-Linear-V2.0 的混合线性架构下进行相同的实验,将 GQA 层替换为 MLA 的效果也更优。这证明了 MLA 具备更优的表征能力,因此我们在 Ling 2.5 架构 中集成 MLA 结构。
解决结构不兼容问题:QK Norm 的数学融合与 Partial RoPE 改造
我们参考了 TransMLA [3] 的思路,将 GQA 模块转成 MLA,但在 Ling-V2.0 架构中遇到了两个不兼容问题:
1、非线性操作阻碍 KV 矩阵吸收:Ling-V2.0 包含 QK Norm 这类非线性操作,这会破坏 MLA 的结构,导致推理阶段无法有效吸收 KV 矩阵。
- 解决方案:我们在转换前移除了 GQA 中的 QK Norm。利用 RMSNorm 的数学特性,通过数据集校准,将 QK Norm 的参数近似融合至 q_proj 和 k_proj 权重中,化解这一矛盾。
2、位置编码的不兼容:TransMLA 原生支持 Full RoPE,而 Ling 2.0架构使用的是 Partial RoPE。
- 解决方案:我们对 RoPE 模块进行了针对性解耦。将受 RoPE 影响的维度与无关维度分开处理。 PCA 、权重旋转等操作仅作用于相关维度,处理完成后再进行拼接,确保了位置编码的绝对正确性。
2. 平滑迁移训练策略
为了最小化架构变更对模型性能的影响,我们基于 Ling-2.0-1T-base-20T(即 20T tokens 的 Pre-Training Checkpoint),设计了一套多阶段的权重转换与渐进式训练(Warmup)策略:
转换至 Lightning Attention 与 GQA 混合的架构
我们沿用 Ring-flash-linear-2.0 方式先将 GQA 转换成 Lightning Attention 和 GQA 混合的架构。具体而言,对 linear_qkv 参数按 head 维度进行扩充,将 GQA 转成 MHA,并对新增参数 gate_proj 和 gate_norm 进行随机初始化。
我们保留了 QK Norm 和 Partial RoPE。一方面是这 2 个操作在 Ling 2.0 架构 中已经存在,保留能减少架构变化带来的影响。另一方面,QK Norm 能强制将 Attention 前的输入范数控制在固定范围内,提升长窗口训练的鲁棒性,同时能减少精度下溢,对 FP8 训练更友好。而保留 Partial RoPE 能解耦位置与语义信息,提升长窗口的性能。
Linear Warmup 阶段
冻结除 linear_qkv 和 qk norm 以外的所有参数。通过 LR Warmup 及少量数据加训,使 Loss 快速下降至转换前同量级的水平。
GQA 向 MLA 的转换
- 去除 QK Norm :去除 QK Norm:采样一批数据,按如下公式将 QK Norm 操作吸收到 q_proj 和 k_proj 中(其中 N 为样本数,d 为 head dim,qij 和 kij 为 q_proj 和 k_proj 在第 i 个样本的各维度输出,Wq 和 Wk 为 q_proj 和 k_proj 的权重,γQ 和 γK 为 QK Norm 的权重),然后移除 Full Attention 中的 QK Norm 模块:
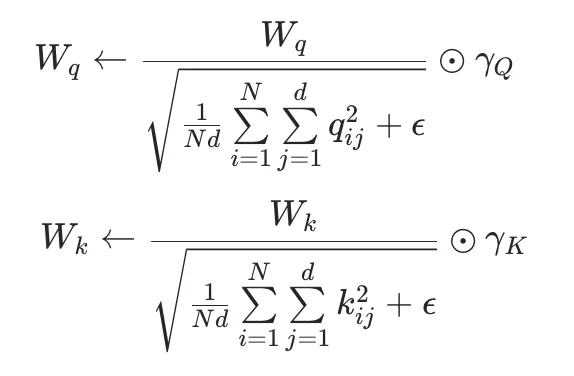
在 Ling 2.0 架构的 mini 尺寸上,该操作使测试集的 ppl 从 6.65 提升到 11.13,模型效果折损可控。接下来我们通过少量的加训进一步减小影响。
-
少量加训:冻结除 linear_qkv 、QK Norm 、gate_proj 和 gate_norm 以外的所有参数,通过 LR Warmup 和少量加训,缓解去除 QK Norm 操作带来的影响。
-
结构转换:执行前文提到的 Partial RoPE 改造与 TransMLA 转换。该操作执行完成后,测试集的 ppl 从 11.13 提升到 11.21,对模型性能影响极小。
MLA Warmup 阶段
冻结未发生结构变化的参数,并通过 LR Warmup 进行少量加训,使 Loss 恢复至改造前同量级水平。
全量训练
各项指标稳定后,解冻所有参数,进行全量参数继续训练。
3. 混合比例的 Scaling Law
我们通过 Scaling Law 实验,探索了 Linear Attention 与 Full Attention 的最佳混合比例,以寻求性能与效率的最优解。如下图所示,在相同计算量(FLOPs)的约束下,实验表明:
-
1:7 比例(Layer Group Size, M=8)展现出最佳的 Scaling 表现,是性能与效率的完美平衡。
-
M=2 和 M=4 的表现虽然接近,但推理成本显著增加。
-
M=16 虽然推理成本极低,但模型 Loss 明显劣化。
-
我们观察到当 FLOPs 向更大尺度 scale 时,Linear Attention 层的占比可以一定程度的变大。
综合考量,我们在 Ling 2.5 架构中确定采用 1:7 的混合比例。
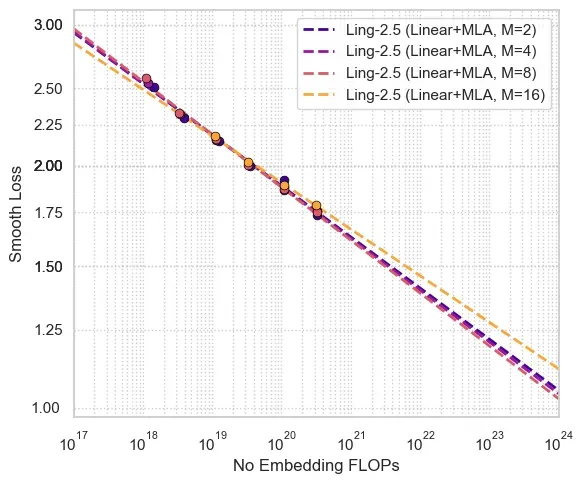
混合比例 Scaling law 曲线
4. 数据切换策略的选择
伴随着架构升级,我们也对 Ling-2.5-1T-base 训练语料进行了优化升级。但在 9T tokens 的加训周期中,何时切入新数据收益最大。
我们对比了两种方案:
-
更保守方案:先用老数据加训 2T + 恢复能力,再切新数据进行加训。
-
更激进方案:在进入全量参数加训的早期,直接切换为新语料。
实验显示激进方案后期效果会更好。 在早期切入质量更高的新数据,不仅初期的效果提升速度更快,仅需加训少量 token 即可恢复效果,训练后期的天花板也更高。因此,在 Ling-2.5-1T-base 的继续预训练中,我们在全量参数加训时候就切成新版本数据。
5. 结语
Ling-2.5 架构 的升级是一次以“降本增效”为核心的务实改造。我们基于 2.0 架构,针对性地引入了 Lightning Attention 和 MLA ,重点解决长文本场景下推理慢和 KV Cache 显存占用高的问题,使模型在超长文本的推理效率和效果上得到双重提升。希望 Ling 这一系列的工程实践,能为面临同样推理瓶颈的同行提供一些切实的参考。
此外,当模型训练或推理的上下文窗口扩展至 256K 或更大时,Ling-2.5-1T 这仅有的 10 层 MLA 占据了超过 60% 的计算成本,我们正在努力寻求下一轮架构升级,以进一步突破 Full Attention 的瓶颈,为实现真正意义上可自主长程工作的通用智能体奠定架构基础。
参考
-
Towards Greater Leverage: Scaling Laws for Efficient Mixture-of-Experts Language Models.
-
Every Attention Matters: An Efficient Hybrid Architecture for Long-Context Reasoning.
-
TransMLA: Multi-Head Latent Attention Is All You Need.