百变人声·身临其境:Ming-flash-omni-2.0 语音生成
1. 模型能力
人声精细化控制
-
基础属性控制, 通过简单指令即可控制生成音频的语速、音量、音调;
-
方言/情感控制, 只需提供任意一句话即可克隆音色,并且通过指令来控制音频的喜怒哀乐,说出地道的粤语和四川话,3 秒速成粤语不是梦!
-
音色设计, 支持自然语言定义音色,内置 100+ 精品音色、以及经典角色音色,无需 prompt 音频,直接获得音色矩阵。
“声临其境”的泛音频统一建模
基于自研连续表征 Tokenizor 和自回归 Diffusion,首次实现了 speech/audio/music 一体化生成。
-
统一连续表征, 为了实现 speech/audio/music 音频信号的统一建模,区别于行业常规离散 Tokenizor,自研表达能力更强的低帧率连续表征 Tokenizor (12.5 Hz),同时达成高效压缩与高保真表达;
-
多 Token 预测(MTP),为了解决长音频生成的曝光偏差问题,在 LLM 层面引入 MPT 策略,将 LLM 推理帧率压缩至 3.1 Hz,显著降低长音频生成步数;
-
非对称补偿 为了解决 speech/audio/music 的信息密度差距大的问题,设计了非对称补偿策略,用更长的记忆换取更大的视野,非对称设计提升了人声在patch生成时的效果,实现泛音频共享生成头。
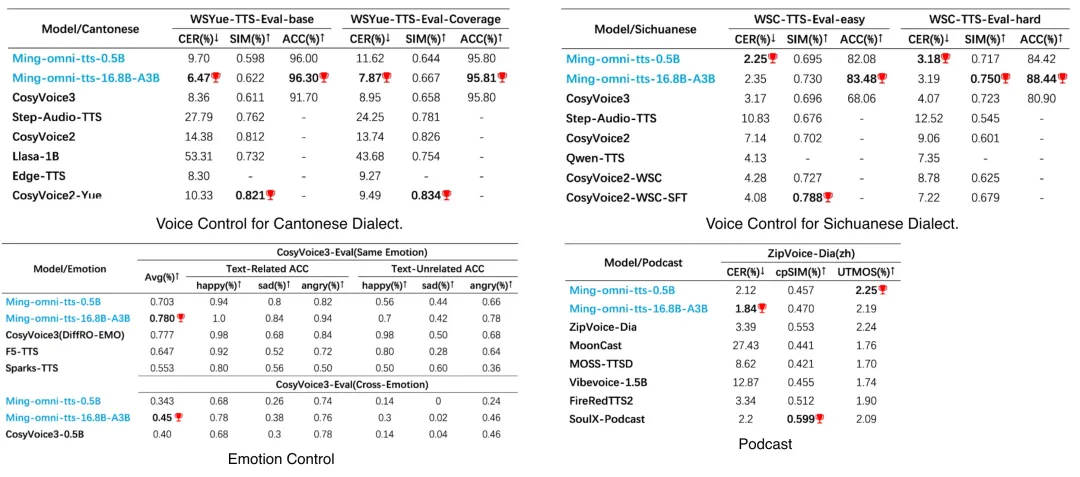
2. 模型指标
Ming-omni-tts 在保证高质量音色克隆的同时,在简洁架构下多个任务上的表现超过/持平专有模型:
-
方言控制:在 WSYue-TTS-Eval 和 WSC-TTS-Eval 上的粤语和四川话生成准确率 96% 和 86%,较 CosyVoice3 提升 2.3% 和 11.5%;
-
情感控制:在 CV3-Eval Emotional 上的平均 acc 为 78%,高于 CosyVoice3;
-
播客风格:在 ZipVoice-Dia-zh评测集上发音稳定性 CER=1.84, UTMOS=2.25,相比专有模型SoulX-Podcast分别提升0.36和0.16;
-
智能正则化:对数学、化学公式正则化任务的 CER 为 1.97%,与 Gemini-2.5 Pro 表现相当。
3. 后续规划
虽然模型对方言、情感等实现精细控制,以及 speech/audio/music 一体化的声临其境的生成,但是依然需要继续优化数据和模型能力:1) 方言支持的范围还比较小,需要更多数据补充;2) 背景音乐支持的配器、流派还局限于强节奏类型的音乐,需要增加更多类型的精细音乐数据;3) 目前还不支持根据文本内容自适应地生成风格匹配的背景音乐和环境音,需要建立文本到音乐、音效的推理能力。
📦 GitHub :
🤗 Hugging Face:
🤖 ModelScope 魔搭社区