超长上下文训练速度翻倍秘籍
TL;DR
大模型长文本训练是通用人工智能竞争的重要高地。将上下文长度从传统的 4k/8k 扩展到 256k 甚至是 1M,主要面临显存压力和计算效率的双重挑战。我们针对 Ling 2.5 架构的万亿参数预训练模型 Ling-2.5-1T-base 提供了工程化解决方案,其中包括:
-
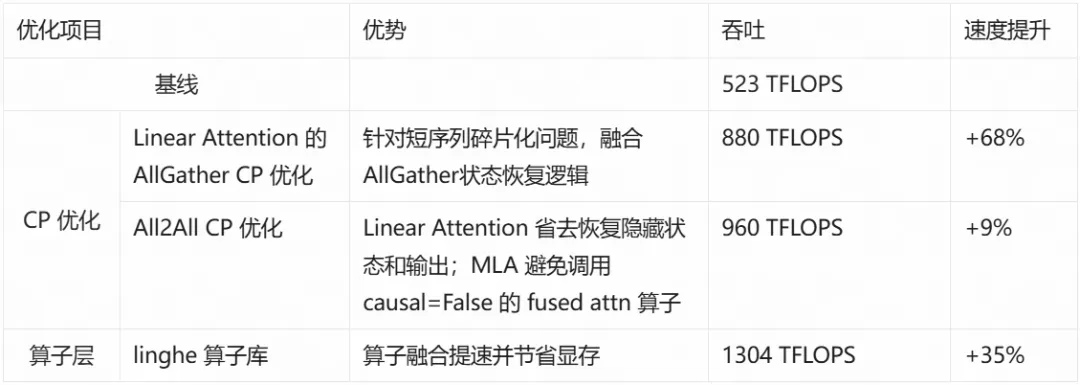
AllGather 形式的 CP(Context Parallel)优化,针对短序列碎片化问题,融合 AllGather 状态恢复逻辑。
-
All2All 形式的 CP 优化,省去恢复隐藏状态和输出。
-
linghe(灵核)高性能算子库融合提速并节省显存。
这些工作在 256K 超长上下文训练中实现 token 吞吐 2.5 倍的提升。本文主要介绍这些工作背后的 knowhow 与 bitter lessons。
1. 超长上下文工作的问题与挑战
Ling 2.5架构采用了混合线性 Attention,这是指模型部分层采用 Linear Attention,部分层采用 MLA 结构,在万亿参数规模下,二者比例是 7:1。在这一架构下,随着文本长度扩展到 256k 甚至是 1M,我们在大模型训练速度的两个最核心优化点:并行方式和算子性能都遇到了挑战。
并行方式
第一,并行方式上,在大模型超长上下文训练中,开启 CP 是突破单卡显存瓶颈的必经之路。但是混合线性 Attention 架构对比传统的 Softmax Attention 架构,开启 CP 过程不仅存在类似的 reduction 类并行难题,也会遇到 Linear Attention 序列之间递归依赖关系问题。
具体来说,在传统的 Softmax Attention 架构下,沿着 tensor 的特定维度做切分的策略,分段间的数据依赖越多,引入的通信算子就越多,性能损耗可能就越大。 对于传统的 reduction 算子,以 RMSNorm 为例,假如沿着 sequence 维度切分,前向计算不存在分段间的数据依赖,但在反向计算 rmsnorm weight grad 的时候,则需要把不同分段间的梯度累加到同一个 weight grad 上,引入 all-reduce 通信,这属于典型的并行 reduction 问题。这个问题在混合线性 Attention 架构中也会遇到。
序列间依赖方面,Softmax Attention 与混合线性中的 Linear Attention 存在本质差异。Softmax Attention 虽然具有全局依赖,但其依赖可被统一表示为矩阵乘法 *QKT,*并通过 softmax 与 mask 在单个算子内高效处理,因此可以通过 block 切分或 ring attention 实现并行。但 Linear Attention 对于每个 token 的 attention 输出,先计算 ht = α ∗ ht-1 + (Kt)T ∗ Vt, 再计算 Ot = Qt ∗ ht (此处省略核函数),其核心是类似 RNN 的递归形式,序列之间有明显的递归依赖关系,无法直接应用矩阵乘法进行并行加速。也就是说,在对序列进行切分时,GPUk 的输入依赖 GPUk−1 输出的状态 h,因此 Linear Attention 不能像传统 Softmax Attention 那样简单切分。
算子性能
第二,算子方面我们发现了多个细碎算子可融合优化的空间。首先是在 Linear 层使用 FP8 GEMM 的计算速度相比于 BF16 GEMM 将大幅提升,但额外的量化操作会带来比较明显的性能负担,这里主要影响 MoE 模块。然后 Attention 层包含了一些耗时较多的前后处理操作,比如 RoPE、gating 等,使得 Attention 模块整体变慢。这些细碎、额外的操作,拖慢了 Ling 2.5 架构中最关键的两个计算:Attention 模块和 MoE 模块。
2. 思考、踩坑和分析
前人工作
首先,团队站在巨人的肩膀上,首先考察了前人工作。来看看哪些工作可以在混合线性架构的 MLA 和 Linear Attention 中使用。
在考察 MLA 的长文本实现中,传统 Softmax Attention 的 CP 实现通常有两种主流路线:Ring Attention 和 Ulysses (All2All)。Ring Attention 在序列维度进行切分,通过 Ring P2P 通信在多卡间流转 KV 块,并根据 online softmax 对每个小块的 attn out 进行修正。而 Ulysses 则是利用 All2All 通信将切分序列维度转置为切分 head num 维度,可保证每个 head 的 sequence 都是完整的,该方法存在 head num 能被 cp size 整除的限制。这两种 CP 实现方式可以被借鉴来实现 MLA 的并行方式。
在考察 Linear Attention 的长文本实现中,可以采用并行扫描算法对序列进行分块来加速计算。目前业界有 FLA (Flash Linear Attention) 是针对 Linear Attention 的高性能算子库。FLA 利用并行扫描算法对具有递归关系的 Linear Attention 进行计算加速。团队一开始认为,将这种分块并行扫描的方式应用到多机上就能实现 CP 了。
团队初期考虑从快速实现的角度出发,复用 FLA 库和尝试 Ring Attention、All2All 并行方式进行混合线性架构适配。
初版性能不佳与问题
从理论到实现,我们很快遇到了一些问题。
踩坑一,MLA 使用 Ring Attention 调用的 cuDNN 性能问题。**在初版实现中,我们用了Ring Attention。在超长上下文训练的实践中却发现当 MLA 结合特定的算子时,Ring Attention 会暴露严重的性能问题。Ring Attention 的核心机制是将长序列切分成多个块,GPU 在计算完本地的 Q 和本地的 K、V 后(即对角线块),需要接收来自其他 GPU 的历史 KV 块进行计算。 在处理历史 KV 块时,历史 token 对当前 Q 是可见的,不需要掩码,因此需要调用 causal=False 的 fused attention 算子。在实际测试中,我们发现底层 cuDNN 实现的 MLA 算子在 causal=False 这种配置下 backward 存在性能问题,算子的性能问题导致 Ring Attention 并不是一个合适的选择。
踩坑二,Linear Attention 部分如果使用简单的实现,会遭遇严重的 kernel launch cpu overhead 问题。**我们以一段描述变长序列(varlen)情形下的伪代码来描述我们的第一版实现:
Input: kv_states: gathered kv_states from all seg-sequence. attn_out: attention out on current seg-sequence. decay: exp(g_gamma * seg_seq_len) scale: 1.0 / head_dim**0.5 seq_num: total number of sub-sequence.
init_state = 0kv_state = 0for i in range(cp_size): # 局部状态恢复阶段 cur_kv_state = kv_states[i] kv_state = kv_state * decay + cur_kv_state if i > 1: init_state = kv_state
query = query * scalefor i in range(seq_num): # 局部输出恢复阶段 sub_query = query[cu_seqlens_q[i]:cu_seqlens_q[i+1]] sub_attn_out = attn[cu_seqlens_q[i]:cu_seqlens_q[i+1]] sub_decay = decay[:cu_seqlens_q[i+1]-cu_seqlens_q[i]] sub_attn_out = (sub_query * sub_decay) @ init_state + sub_attn_out在初始版本的朴素实现中,我们直接采用 for 循环处理序列数据的恢复与计算逻辑。然而,在长序列场景下,CP size 通常较大(可达 16 或 32),而在可变长度序列(varlen)场景中,单个输入序列可能由大量短子序列组成(数量最高可达百级)。这种设计导致以下关键性能瓶颈:
-
局部状态恢复阶段(伪代码第 8–12 行):需要遍历所有 CP rank 的状态数据,触发大量离散的 GPU kernel 启动(kernel launch)。
-
局部输出恢复阶段(伪代码第 17–21 行):需对每个子序列执行独立遍历,同样引发高频 kernel launch 操作。
如下图是两个过程的前反向timeline

forward timeline
 backward timeline
backward timeline
上述过程因频繁执行小规模 kernel 启动,产生了显著的 CPU 开销(包括调度和同步成本),严重拖累 GPU 计算效率。尤其在反向传播过程中,该问题进一步放大,导致整体训练吞吐量明显下降。
总体而言,在初版的实现中,我们打开 CP 并行的吞吐速度对比短文本不开 CP 的实现,**仅有后者的30%速度性能。
**踩坑三:针对琐碎算子的融合优化,有意想不到的算子精度问题。**比如我们没想到 Triton 本身有计算精度问题:当前 linghe 算子库的实现主要基于 Triton 框架构建,Triton 在 I/O 密集型场景下展现出较高的开发效率,其性能表现相较于朴素的 CUDA C++ 实现具有一定优势,然而,Triton 存在特定条件下的计算正确性问题导致团队踩坑。本项目在 linghe 代码仓库中记录了一个可稳定复现的案例:在未识别该问题源于 Triton 之前,团队投入大量精力进行代码排查与逻辑简化,均未发现逻辑层面异常。最终通过调整 num_warps 参数配置使结果恢复正常,进而确认特定参数组合会触发此计算错误。
此外,Triton 的异步执行特性可能引入非预期的竞态条件(Race Condition)。例如,在融合的交叉熵(Cross-Entropy, CE)算子中,分块写入
(Block-wise Write)与标量读取(Scalar Read)操作共存。由于读写操作并非必然由同一线程处理,可能导致读取到尚未完成写入的数据。此类问题在单元测试阶段难以有效检出,往往在模型正式训练过程中才显现,表现为 Loss 逐渐产生难以察觉的偏差,最终需耗费较多精力定位至具体算子及其根本原因。
思考
在经过初版踩坑后,对于 cuDNN 的算子性能问题,我们一方面重新审视并行方式的实现,舍弃 RingAttention,使用别的并行方式来绕过 causal = False 的算子调用。另一方面,对于频繁触发的 kernel launch 问题,后续优化需重点是减少 kernel 启动频率,例如通过算子融合、以及批处理或向量化操作来合并循环遍历任务。
3. 实现、改进与升华
经过对第一版的分析与总结,我们改进了以下技术方案,进行如下正式实现:
AllGather CP 并行加速
我们开发了 AllGather 的 CP 方式,应用在 Linear Attention 中,其将每个 GPU 上序列片段的局部隐藏状态聚合到一起后,修正最终的 attn out,主要分为两部分:
-
intra-GPU (块内):将完整的长序列切分成 cp size 个块,在块内,每个 GPU 计算自己负责的序列片段的局部隐藏状态和局部输出,这部分计算可以复用 FLA 的高性能 kernel。
-
inter-GPU (块间):通过 AllGather 将每个 GPU 的局部隐藏状态(大小为 [B,H,D,D]) 进行聚合,拿到所有局部状态后,修正各自的局部输出。FLA 计算局部状态和局部输出是由两个 kernel 完成的,对局部状态的 AllGather 通信可以和 O 的计算 overlap 起来,如图-1所示。
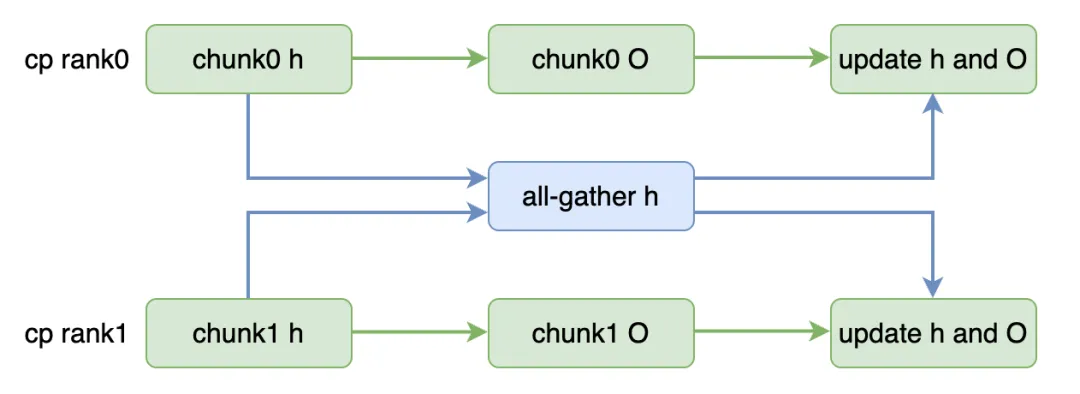
Linear Attention 的 AllGather CP 实现
变长序列(varlen)的 CP 实现
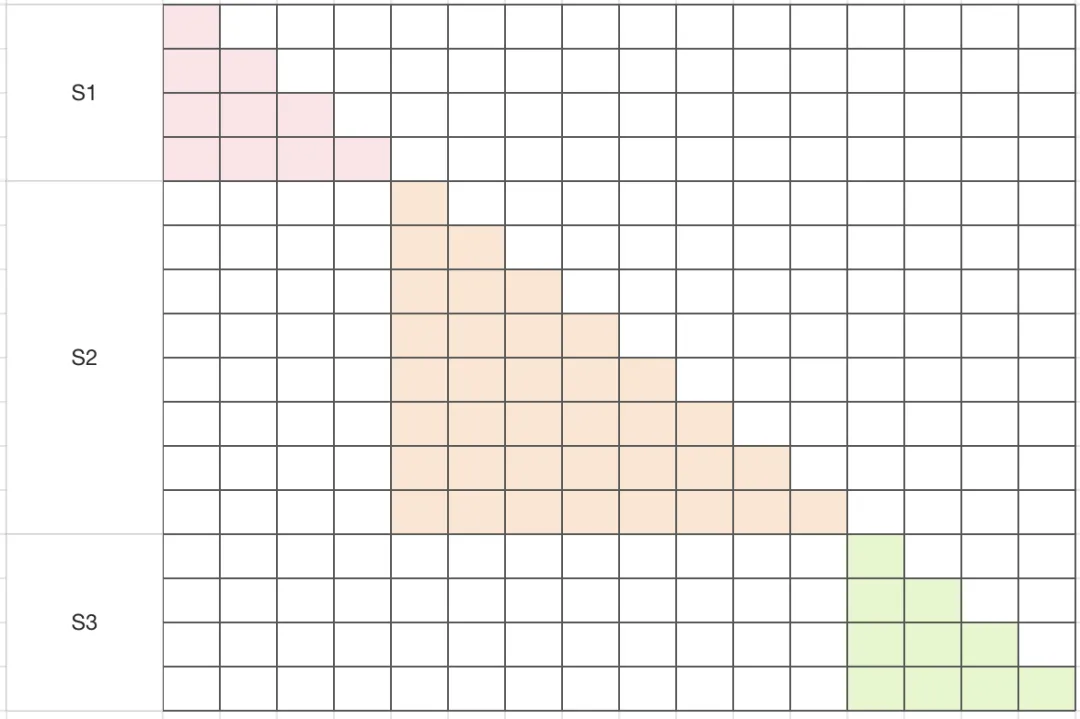
varlen 序列的 attention mask
在处理 CP 场景下的变长序列时,相比序列长度固定的 causal attention 要略微复杂一些,在进行 CP 切分时,将每个子序列都要切分成 CP size 份,在恢复局部隐藏状态和局部输出时更加繁琐,需将子序列数量扩展到 batch size 维度,将每个子序列当成独立的序列来处理,decay 按最大长度来生成。遍历各个序列片段的隐藏状态 kv states 来修正各自的局部状态,再通过正确的 kv states 来更新 attn out。
这个计算过程内,曾经踩坑的问题,我们通过以下优化手段解决了:
-
局部状态恢复阶段(伪代码第 8–12 行):将 for 循环展开并向量化,利用矩阵并行计算优势,减少 kernel launch 次数。
-
局部输出恢复阶段(伪代码第 17–21 行):使用 triton 融合算子加速计算
两个优化在 256K 序列下可整体提升训练速度 70% 左右。
Input: kv_states: gathered kv_states from all seg-sequence. attn_out: attention out on current seg-sequence. decay: exp(g_gamma * seg_seq_len) scale: 1.0 / head_dim**0.5 seq_num: total number of sub-sequence.
init_state = 0kv_state = 0for i in range(cp_size): # 循环展开并向量化 cur_kv_state = kv_states[i] kv_state = kv_state * decay + cur_kv_state if i > 1: init_state = kv_state
query = query * scalefor i in range(seq_num): # 使用 triton 融合算子加速计算 sub_query = query[cu_seqlens_q[i]:cu_seqlens_q[i+1]] sub_attn_out = attn[cu_seqlens_q[i]:cu_seqlens_q[i+1]] sub_decay = decay[:cu_seqlens_q[i+1]-cu_seqlens_q[i]] sub_attn_out = (sub_query * sub_decay) @ init_state + sub_attn_outAll2All CP 并行加速

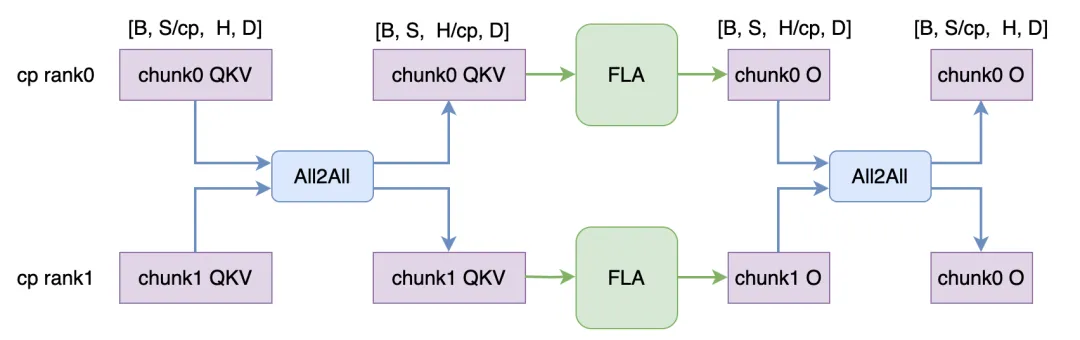
All2All CP 实现
借鉴 Ulysses 方案,我们开发了 All2All 的 CP 实现。这种并行方式利用其通信特性,将“切分序列维度”转置为“切分 Attention Head 维度”,QKV 经过 All2All 通信后序列这维是完整的,可以直接复用 FLA 的 kernel,之后将 attention out 再经过一次 All2All 恢复成原来的切分,计算流程如上图所示。
在 Linear Attention 和 MLA 上,我们都适配了这种 All2All 的 CP 方式。**在 MLA 上可以绕开第一版中有性能缺陷的 causal=False 的算子调用。**在 Linear Attention 上,尽管 All2All 的实现没有更新局部隐藏状态和局部输出的过程,但由于 All2All 通信是同步阻塞的,无法和计算 overlap 起来。不过相比 AllGather 的实现,整体性能提升还有 5% 左右。
不管是 Linear Attention 还是 MLA,All2All 的 CP 实现都很简洁高效。不过该方法存在 cp size 不能大于 head num 的要求,在未来探索超长文本的训练时会受到限制,因此百灵团队同时提供 Linear Attention 上 AllGather 和 All2All 的并行方式。同时团队也在更长远的架构和并行方式设计中(如结合张量并行或优化 MLA 的 Head 维度设计)进一步探索。
linghe 灵核高性能算子库
在本次 Ling-2.5-1T-base 的训练中,我们也针对细碎算子可融合优化的空间,从以下角度进行了性能优化:
1.Linear 层计算优化:相比于 BF16 GEMM,FP8 GEMM 计算速度大幅提升,但额外的量化操作会带来比较明显的性能负担。以百灵模型为例,RMSNorm/SiLU 后紧接着为 linear 层(fp8 gemm),我们很自然的可以将量化操作和前继算子进行融合,减少一次 BF16 结果的写读操作,既降低了算子耗时,也能避免 FP32 到 BF16 类型转换带来的精度损失。
2.Attention 层计算优化:Attention 层包含了一些耗时较多的前后处理操作,比如 RoPE、gating 等。Ling 2.5 架构中 MLA 和 Lightning Attention 交替排列,我们对两者的 RoPE 进行了针对性优化。对于 Lightning Attention 部分,我们将 split qkv、q/k norm,q/k CP RoPE 等操作融合为一个算子;对于 MLA 部分,我们替换基线方案里面 q RoPE + kv RoPE 两个算子的方案为一个单算子的方案,降低了一次 triton kernel launch 时间,也降低了一些公共参数的重复读取,另外还优化了 Q/K 的访存连续性,通过连续读之后应用 permute + flip + permute 来避免低效的 interleave 读取。对 Lightning Attention 里面的 group rms norm + sigmoid gate 也进行了融合。
3.其他优化:
- permute 优化: FP8 gemm kernel 要求运算矩阵 shape 是 16 的倍数,而在 MoE 模型中分发到每个 expert 的 token 数量是随机的。在数学等价的前提下,我们通过编辑 DeepEP backend 输出的 routing map 的方式保证了 permute 后矩阵 shape 的兼容性,并将 permute 和量化操作融合,相比于原有 tensor padding / unpadding + 独立量化操作的策略,可进一步提升模型训练效率。
- 重计算状态感知优化: 对于 blockwise 量化算法,前向需要激活的 rowwise 量化结果作为输入,反向需要 columnwise 的量化结果作为输入,因此可以通过感知重计算的状态,在非重计算的 forward 阶段不计算 columnwise 的量化结果,降低一部分耗时。
- 损失函数及 batch 操作优化: 对 cross entropy loss、z loss 等进行融合; 将优化器里面的多个梯度统计操作进行优化,从序列操作融合为 batch 操作来降低耗时。
需要注意的是,融合算子不仅可以降低算子耗时,还可以降低显存消耗。一方面不需要存储多个中间计算过程的激活值,另一方面可以避免存储 FP32 的高精度激活值。节省的显存可进一步为模型
TP/PP/CP、重计算、MBS 等策略调整带来更大的优化空间。
以下为整体的算子融合 Overview:
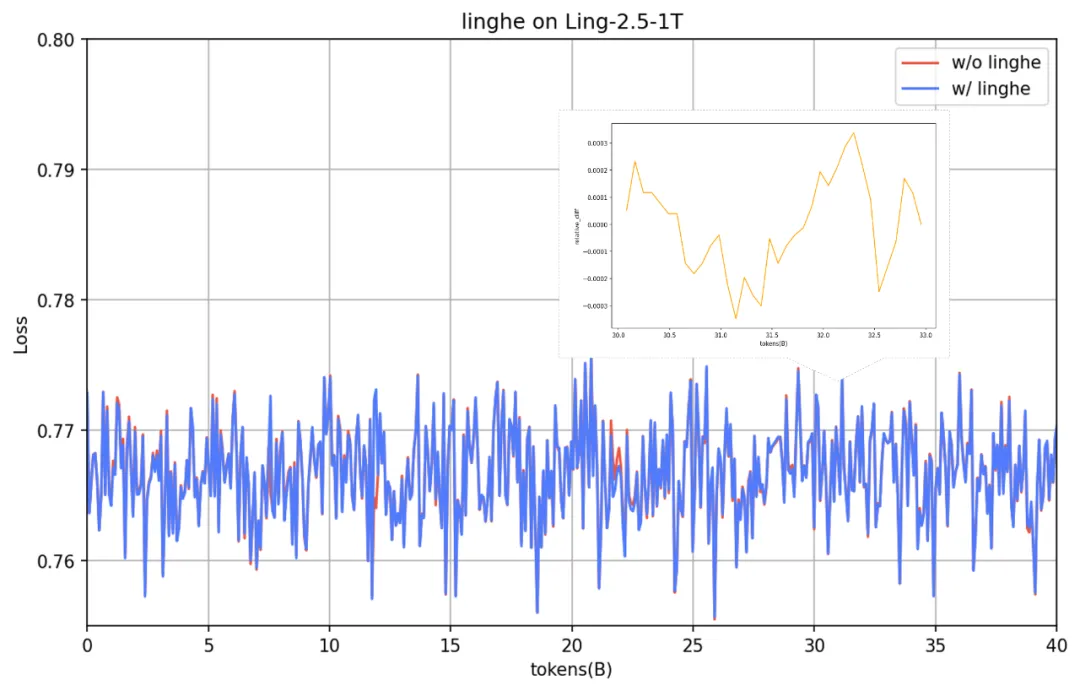
精度对比
**针对踩坑的精度问题,团队进行了细致的对比和排查。**下图展示了我们在 Ling-2.5-1T-base 训练过程中对比开启 linghe 相关融合算子前后的 loss,其收敛趋势与基线一致,且 loss diff 均值约 0.00001。引入 linghe 算子库可在精度无损的情况下带来不错的性能收益。
性能对比
256K 超长上下文训练对显存的消耗较大,在开启全量重计算之后,依然需要增加流水线级数来降低单卡的显存压力,进而导致空泡增加 MFU 下降,而 linghe 融合算子降低了激活显存峰值,进而可以降低流水线级数,获取算子加速外的额外收益。在 Ling-2.5-1T-base 的 256K 超长上下文训练过程中,我们通过以上优化,实测在显存仅增加 2.8G 的情况下,可额外带来 43.7% 的性能收益。
5. 结语
我们将上面介绍到的多项技术进行最终整合,在实验性的上下文训练整合测试中进行了性能对比:
这些优化从显存优化和计算效率两个角度,解决显存瓶颈,降低显存峰值,减少 Kernel Launch,融合算子提升计算效率和访存效率,叠加所有优化点后,最终的训练速度达到基线的 2.5 倍左右。